【無料】Google Apps Scriptでwebスクレイピングを行う方法。動的&静的ページどちらも可能。

こんな人におすすめ
簡単にweb情報を取得したい。
Google Apps Scriptでwebスクレイピングを行いたい。
今回は、Google Apps Scriptでwebスクレイピングをする方法を解説していきます。
目次(クリックで読みたい部分にジャンプできます)
Google Apps Scriptでwebスクレイピングを行う利点は?

そもそも、Google Apps Scriptでwebスクレイピングをする利点はなんでしょうか?
一番が手軽さだと思います。
Google Apps ScriptはGoogle アカウントさえあればできますし、サーバー代やスプレッドシートを使えばデータベース代などの余計な費用もかかりません。
サーバーへのアップロード作業もいらないので、余計な手間が減ります。
またスクレイピングは自動実行が必要ですが、Google Apps Scriptでもそれが標準で用意されています。使いやすいです。
これらの理由から、webスクレイピングは、Google Apps Scriptでやるのが向いているというわけです。
⚠️注意⚠️ Google Apps Script で取得できないページとは

Google Apps Script でも取得できないページが存在します。
取得できないページ
①ログインなどを必要とするページ
②URLを指定して、直接そのページに行けないページ
これらは、セッションなどの情報が必要だったり、直接URLで指定のページに飛ぶことができないのがそれにあたります。

URLを指定して、直接表示できるページは、Google Apps Script で取得可能です!!
静的ページを取得する場合の方法

【準備編】Parserライブラリの追加
今回は、スクレイピングをするのにとても便利な「Parser」ライブラリを追加していきます。
IDは以下です。
ID
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw

追加できたら、コードを書いていきましょう!
コードの追加
コードの追加の流れは次のような感じです。
コードの流れ
①特定のURLのHTML情報(文字情報)を取得してくる
②Parserライブラリを用いて、取得したい箇所を指定して、取得。
何を言っているのかわからないかもですが、コードを書いていきながら理解していきましょう。
今回取得するページ
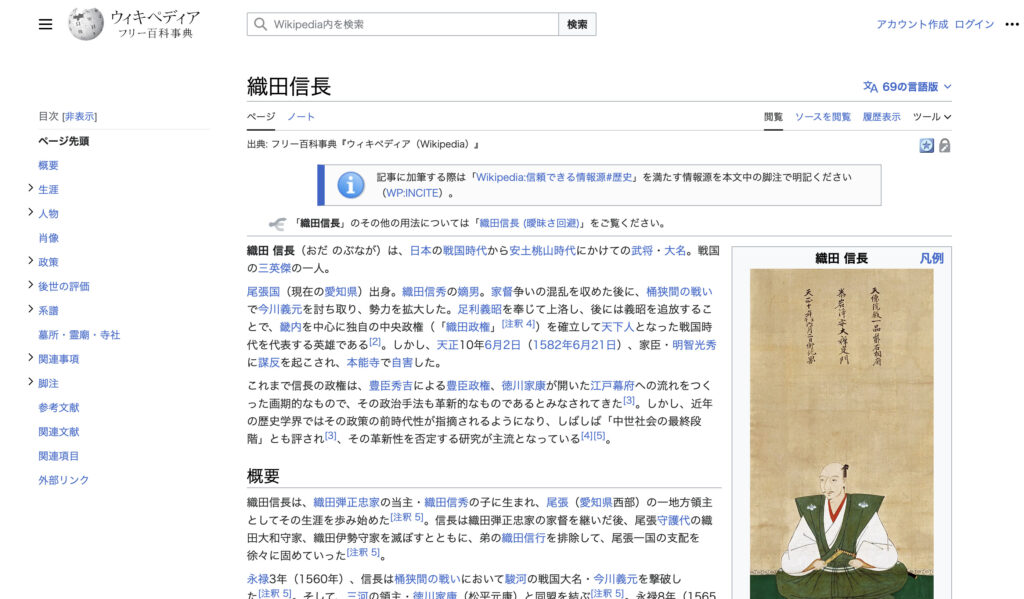
では、以下のコードをコピペしてみてください。
function get_pageinfo() {
let url = "https://ja.wikipedia.org/wiki/%E7%B9%94%E7%94%B0%E4%BF%A1%E9%95%B7"
//①の部分
var html = UrlFetchApp.fetch(url).getContentText('UTF-8');
console.log(html);
//②の部分
var result_iterate = Parser.data(html).from('<span class="mw-page-title-main"> ').to('</span>').iterate();
var result_build = Parser.data(html).from('<span class="mw-page-title-main"> ').to('</span>').build();
console.log(result_iterate);
console.log(result_build);
}コードの解説
①「特定のURLのHTML情報(文字情報)を取得してくる」
まず、流れで言う①の部分
「特定のURLのHTML情報(文字情報)を取得してくる」
を以下コードで行っています。
var html = UrlFetchApp.fetch(url).getContentText('UTF-8');
console.log(html);実行した時に、たくさん文字が出てきたはずです。
出力した文字が、ページ内(今回だと、wikipediaの織田信長ページ)のHTML情報になっています。
この文字情報から、自分が欲しい情報を取得していきます。
今回は、一番上の「織田信長」の文字が欲しいとしましょう。
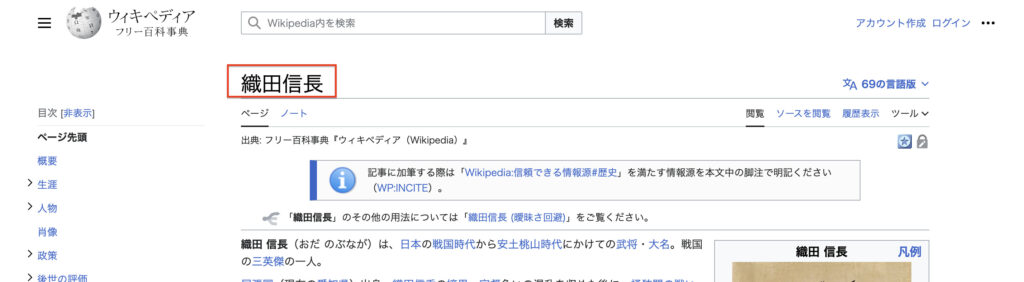
②Parserライブラリを用いて、取得したい箇所を指定して、取得。
Parserライブラリはwebスクレイピングをするときに、とても便利なものです。
使い方は、取得したい文字列の「前後の文字」を指定するというものです。
前後の文字の見つけ方
前後の文字を見つける方法を解説します。
前後の文字を見つけるためには、まずページを開いてから、右クリックで「開発者ツール」「検証」と言うものがあるのでそれをクリックします。
すると、以下のように、画面右がわにページのHTML情報が表示されます。
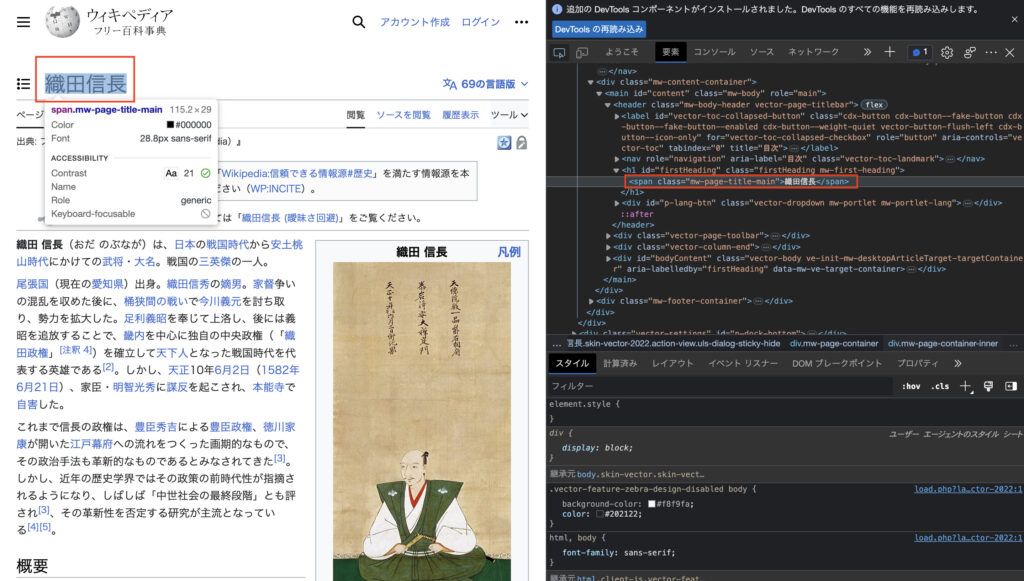
今回は、「織田信長」という文字を取得してきたい場合は、右の赤枠の部分に書いてある
【前】 <span class="mw-page-title-main">
【後】 </span>
のようになります。
前後の文字を見つけたら、以下のコードのform toのところに当てはめます。
Parser.data(html).from('<前>').to('<後>').iterate();iterate() , build() の違い
iterate と build の違いを解説していきます。
iterate() は複数選択、配列で表示されます。
そのため、条件に一致しているものは、すべて取得されます。
一方、build() は条件に合う、最初の一つを取得します。
そのため、配列でなく、文字単体で表示されます。

先ほど示したコードの中に、2つ表していると思います。
実行ログで表示されるようにしていますので、違いを見てみてください👍
ここまでで、静的ページのwebスクレイピングの解説は終了です!お疲れ様でした!
動的ページを取得する場合の方法
動的ページを取得する方法は、次の記事で解説しています。
下から飛べます🛫

