【Python】BeautifulSoupを使って簡単にスクレイピングしよう!【初心者向き】

「Pythonでスクレイピングしてみたい」
「ページから要素を取得してみたい。」
今回はこのような方を対象に記事を書いています。
この記事では、PythonのモジュールBeautifulSoupを使って簡単にスクレイピングをする方法・コードをご紹介します。
コードは実際に実行して動くことを確認していますので、コピペで自分の環境で実行してみてください。
目次(クリックで読みたい部分にジャンプできます)
BeautifulSoupとは
BeautifulSoupとはPythonのスクレイピングライブラリーの一種です。
スクレイピングとは、webページの中の特定の要素を取得することを言います。
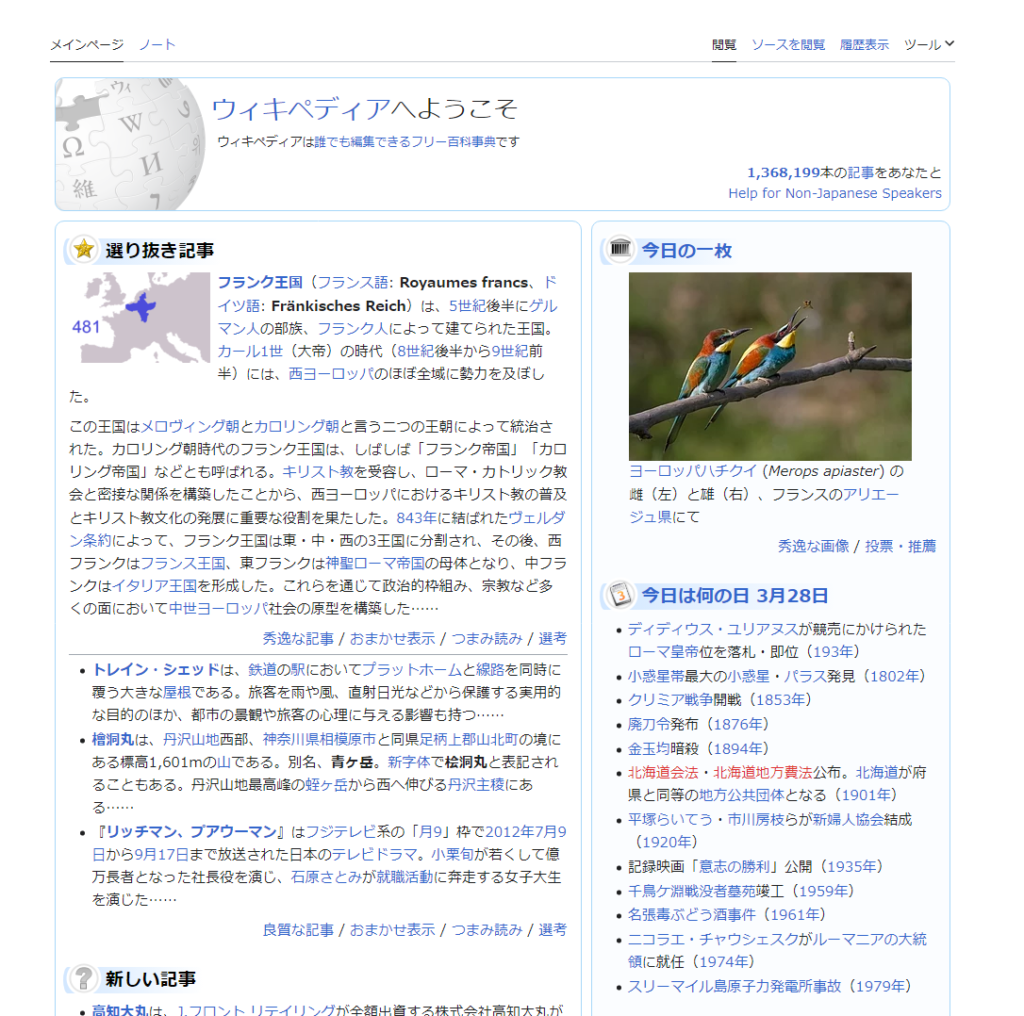
例えば、上記の画像は「wikipedia」のランディングページです。
この中には、タイトル、や選り抜き記事や今日の一枚、今日は何の日、などの要素があります。
「今日は何の日の情報を定期的に得たい!」と考えたときに、スクレイピングを実行することで、得たい情報のみを簡単に得ることができます。
このように、他のサイトに訪れてその情報を抜き出すことがスクレイピングであり、それを簡単に実行できるのがBeautifulSoupというわけです。
全体の処理の流れ
それぞれのコードを見る前に、まず処理の流れを確認しましょう。
- URLにアクセス&要素を取得
- 要素に連番をつける
- csvに保存
以上の順番で処理を進めていきます。
ちなみに、csvに保存しなくてもよくて、ただprintだけすればよいという場合は、二つ目の「要素を取得」までで大丈夫です。
今回は、wikipediaの今日は何の日をスクレイピングしていきたいと思います。
URLにアクセス
#1.URLにアクセス
url = "https://ja.wikipedia.org/"
response = requests.get(url)
#2.要素を取得
soup = BeautifulSoup(response.content, "html.parser")
today = soup.find("div", attrs={"id": "on_this_day"})
entries = today.find_all("li")requests.get()で、HTTPレスポンスを取得します。
HTTPレスポンスとは、URLにアクセスしたときにサーバーから返ってくるHTMLのことを言います。
なので、BeautifulSoupでは、返ってきたHTMLから特定の要素を引き出します。
BeautidfulSoup()で、HTMLをタグ単位に分けます。
今回は、「今日は何の日?」をスクレイピングするので、wikipediaのページで開発者ツールを見ると、
divタグ、でid=on_this_dayとなっているのがわかりますので、.find()で抽出します。

.find_all()で抽出したdivタグ内のli要素を全て取得します。
要素に連番をつける
today_list = []
for i, entry in enumerate(entries):
today_list.append([i + 1,entry.get_text()])enumerate()でentriesがなくなるまで、i とentryを繰り返します。
これで、連番はついたので、この後CSVに保存を行いますが、
print(today_list)で連番にした内容を表示することも可能です。
ここまででよいという方は、コードもここまでで大丈夫です。
csvに保存
with open("output.csv", "w", encoding="utf_8_sig") as file:
writer = csv.writer(file, lineterminator = "\n")
writer.writerows(today_list)with open でoutput.csvというファイルを用意します。
encodingは他の方法だと私は文字化けしてしまうので、utf_8_sigを指定しています。
これでうまくいかない方は、encoding=SHIFT_JIS , encoding=utf_8などを試してみるとよいと思います。
全コード
import requests
from bs4 import BeautifulSoup
import csv
import re
url = "https://ja.wikipedia.org/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
today = soup.find("div", attrs={"id": "on_this_day"})
entries = today.find_all("li")
today_list = []
for i, entry in enumerate(entries):
today_list.append([i + 1,entry.get_text()])
with open("output.csv", "w", encoding="utf_8_sig") as file:
writer = csv.writer(file, lineterminator = "\n")
writer.writerows(today_list)まとめ
今回は、BeautifulSoupを使ったスクレイピングを紹介いたしました。
PythonにはBeautifulSoupのようなモジュールは他にもあり、その一つにseleniumがあります。
seleniumは自動検索などを可能にしますので、ぜひ試してみたい方は以下の記事も併せて読んでみてください。


