spreadsheetを一括でexcel形式にダウウンロードする【python自動化】(その1)
-1024x576.jpg)
「spreedsheetを一括でダウンロードしたい。」
「spreedsheetからexcelにサービスを移行したいと考えているけど、ファイル多すぎてダウンロード大変」
私自身もそうでした。会社の中で、spreedsheetから試験的にexcelに移行してみたいという話が出ていました。そのためには、spreedsheetをダウンロードしてexcelに移行する必要があるのですが、spreedsheetには一括ダウンロードができなく、一つ一つ手作業でやる必要がありました。(何百ファイルとなるとめちゃ大変でした)
今回は、pythonのseleniumを使って、ダウンロードするまでの一連の作業を自動化していきたいと思います。
こちらを用いれば、スプレッドシート一覧から一括でダウンロードが可能になります。ぜひ一気にダウンロードをしたいという方は、試してみて下さい。
目次(クリックで読みたい部分にジャンプできます)
GoogleSpreedSheetは一括ダウンロードができない
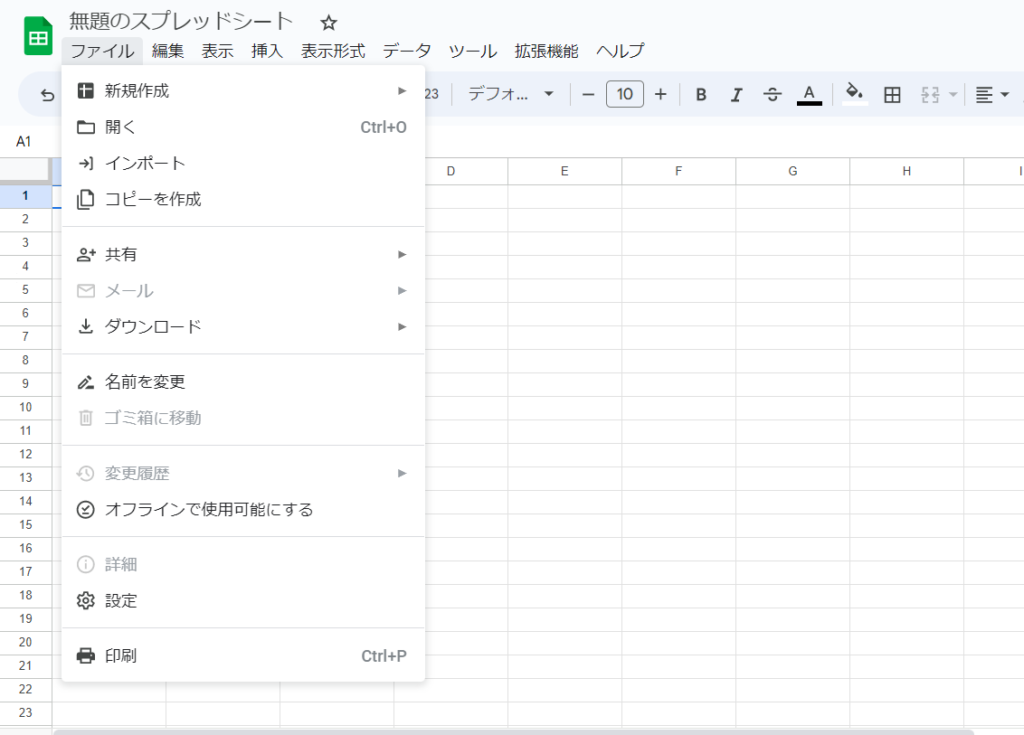
SpreedSheetを一括でダウンロードする方法はありません。(もしどこかで一括でダウンロードするツールがあったら教えてほしいです)
もしダウンロードをしたい場合は、ファイルを一つ一つ開いて、メニューの「ファイル」から「ダウンロード」を選び、Excel形式か自分のダウンロードしたい形式を選んで行います。
これでは、ダウンロードしたいファイルが何百ファイルもある場合は、作るのがめちゃくちゃ大変になります。
今回はこの作業を自動化できないかと考えました。
解説の順番
解説の順番
①Googleアカウントでログインし、各SpreedSheetのURLを取得する←(今回はこれ)
解説は、この2ステップで行います。今回は各ファイルのURLを取得するところまでをやっていきます。
前準備
今回の自動化にはPythonのseleniumとwebDriverなどを用います。まず最初に準備しておくことがあるので準備しておきましょう。
- Python
- selenium
- ChoromeDriver
- SpreedSheetを閲覧できるアカウントのプロフィールパスを取得
- Chromeのバックグラウンドインスタンスの停止
Python やselenium、ChromeDriverのダウンロードは他のサイトでも載っているのでここは割愛します。
SpreedSheetを閲覧できるアカウントのプロフィールパスを取得
SpreedSheetにログインできるアカウントでChromeにログインしましょう。
ログイン後、URLで以下を検索します。
chrome://version
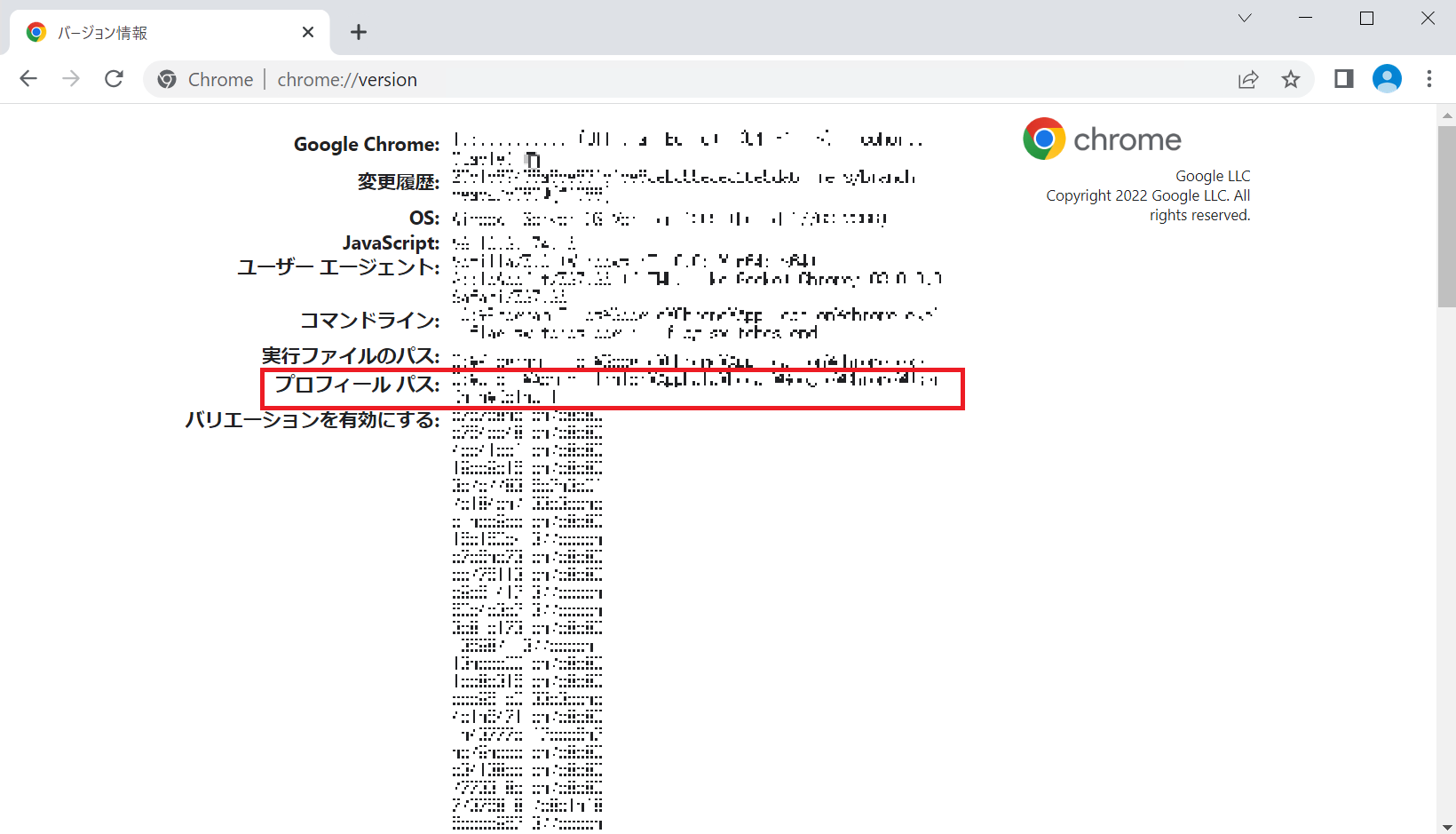
こちらのプロフィールパスの部分を後で使うので、このページを参照できるようにしておいてください。
Chromeのバックグラウンドインスタンスの停止
今回Pythonのseleniumを使いますが、Chromeを操作する際にChromeのインスタンスが実行されていてはエラーが起きます。
そのため、Chromeをバックグラウンドの実行を止める設定をします。
Chormeの右上の「3ポチ」(三つの点があるやつ)をクリックして、その中の「設定」を選びます。
すると、以下のように設定画面がでるので、左のメニューバーから「システム」を選びます。
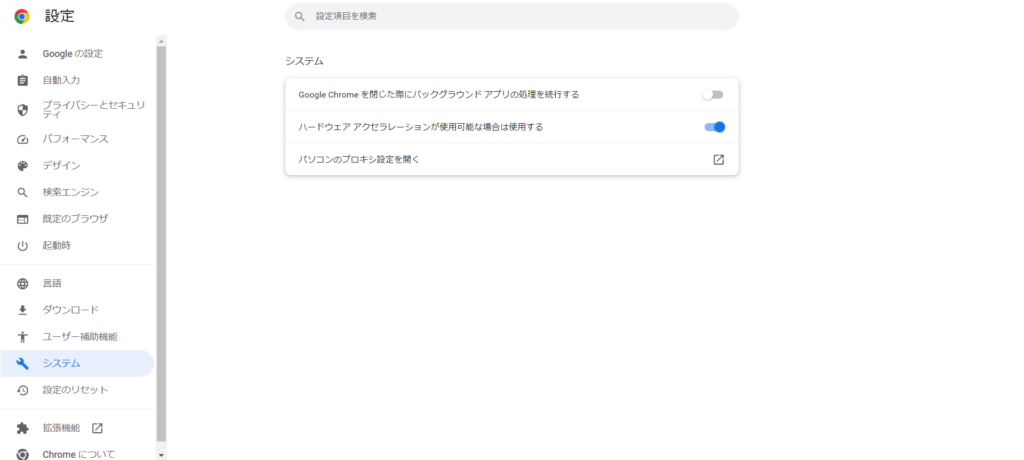
「GoogleChromeを閉じた際にバックグランドアプリの処理を続行する」をオフにします。
コード解説
# 時間を計るライブラリをインポート
import time
# WebDriverライブラリをインポート
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
# ChromeのWebDriverライブラリをインポート
from selenium.webdriver.chrome import service as fs
#ChromeDriverのパスを指定
#今回は同じディレクトリに置いている。
CHROMEDRIVER = "chromedriver.exe"
# ドライバー指定でChromeブラウザを開く
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
options = Options()
#以下を加えないとエラーが出る場合があった。(今はない)
#options.add_argument('--headless')
options.add_experimental_option('detach', True)
# プロファイルの保存先を指定
# <ユーザー名>は変更してください。以下2行注意点あり。
options.add_argument("--user-data-dir=C:/Users/<ユーザー名>/AppData/Local/Google/Chrome/User Data")
# 使用するプロファイルを指定
options.add_argument("--profile-directory=Profile 1")
driver = webdriver.Chrome(service=chrome_service, options=options)
# Chromeを開いてスプレッドシート一覧にアクセスする
driver.get('https://docs.google.com/spreadsheets/u/0/')
#時間を置く。
time.sleep(5)
SearchClass = "docs-homescreen-list-item docs-homescreen-item-shared"
num = 0
count=len(driver.find_elements(By.XPATH,"//*[@class='docs-homescreen-list-item docs-homescreen-item-shared']"))
hover = []
#以下のcountを変えることで、回数を変更可能(最大45件。スクロール制御を加えればさらに多くを取得できる)
for i in range(count):
#以下のclassの値(docs-home~~)が違うかもしれないので、「存在しない」エラーが出た場合サイトを確認してみてください。
hover=driver.find_elements(By.XPATH,"//*[@class='docs-homescreen-list-item docs-homescreen-item-shared']")
time.sleep(1)#ロードができていない場合、取得できない場合があるので、間隔をあけている
print(len(hover))#ここでhoverの数が0の場合は読み込めていないとき。対策は、time.sleepを長くするか、hoverが0以外の時にのみ処理を実行するか。
hover[num].click()
print(driver.title)
print(num,":",driver.current_url)
driver.back()
time.sleep(2)#同様に間隔を空けている(hoverが0の時は再度処理をやり直すのを組み込んでも良い)
num = num + 1
time.sleep(5)
#スクリーンショットを撮影したい場合
#driver.save_screenshot('selenium_schreenshot_test2.png')
time.sleep(5)
# 画面を閉じる。インスタンスを終了する処理を組み込まなければ、次に実行したときにエラーになる可能性がある。
driver.quit()
「プロファイルの保存先を指定」と「使用するプロファイルを指定」とするところは、先ほど準備した、プロフィールパスを使用します。
注意点として、
--user-data-dir=C:/Users/<ユーザー名>/AppData/Local/Google/Chrome/User Data
の部分で、User Dataの間にスペースを必ず設けましょう。設けないとエラーとなります。
また、「使用するプロファイルを指定」のところは、プロフィールパスの「~~Data\<ここに記載してあるもの>」を記載しましょう。
このpythonファイルを実行すれば、ファイルのURLが取得できるはずです。
エラーが出た場合
エラーパターン①
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 18-19: truncated \UXXXXXXXX escape
このエラーの場合は、
options.add_argument("--user-data-dir=C:/Users/<ユーザー名>/AppData/Local/Google/Chrome/User Data/")この部分で「\」となっている可能性があります。
全て、「/」となっているか確認しましょう。
エラーパターン②
エラーの原因として考えられるのは、GoogleChromeのインスタンスが実行されている可能性が考えられます。
バックグラウンドでGoogleChromeが実行されているかを確認してみてください。実行されている場合は、それを終了することが必要です。
もちろん、フォアグラウンドで通常でChromeが開いていてもダメなので、全てウィンドウは閉じるようにしましょう。
バックグラウンドで動くChromeを停止させる
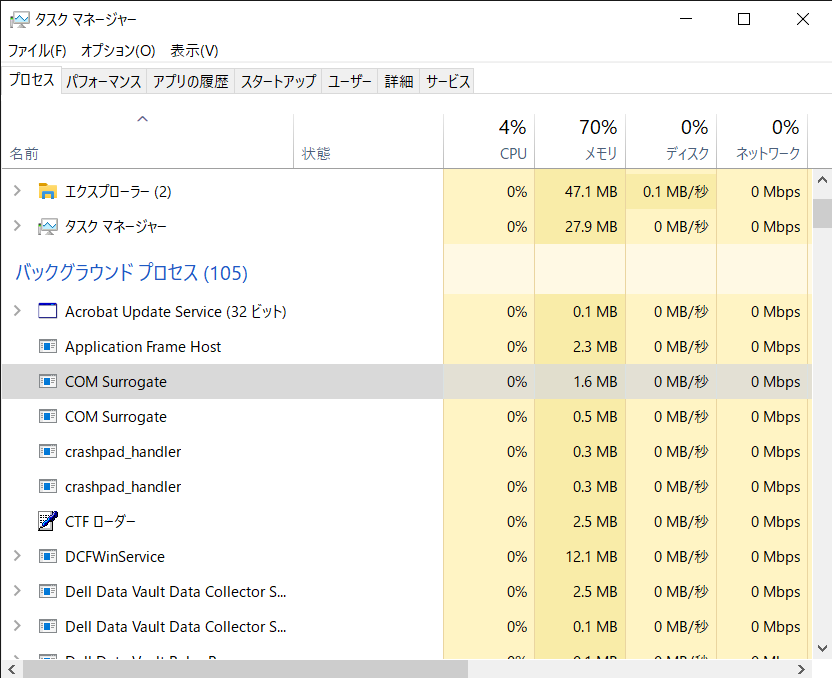
①スタートメニューから、「タスクマネージャー」を選択します。
②「プロセス」の中の、バックグラウンドプロセスで、GoogleChromeが実行されていないか確認します。
③実行されている場合は、選択して「タスクの終了」を行います。
今回はここまで
今回は、GoogleSpreedSheetのダウンロードをpythonのseleniumでURLを取得する方法まで解説しました。
次は、URLを取得したところから、ダウンロードをするところを実装していきますので、そちらも合わせてご覧ください。
-150x150.jpg)

-300x169.jpg)