spreadsheetを一括でexcel形式にダウウンロードする【python自動化】(その2)
-1024x576.jpg)
この記事は、以下の記事の続きになります。以下の記事をよんでからの方がより理解ができるかと思います。
spreedsheetを一括でexcel形式にダウウンロードする【python自動化】(その1)
今回の(その2)の記事では、紹介したコードをパソコンのセットアップゼロからの状態でやっていきます。実際にあなたの環境でも動かせるように紹介していきますので、最後までご覧ください。
目次(クリックで読みたい部分にジャンプできます)
順番
解説の順番
①Googleアカウントでログインし、各SpreedSheetのURLを取得する
②URLを加工し、ダウンロードする←(今回はこれ)
今回は、取得したURLをもとにダウンロードを行っていきます。
「前回までの処理」と「今回行う3つの処理」
前回は、ログインを突破し、一覧に載っているそれぞれのSpreedSheetをダウンロードするところまでを行いました。
今回は、取得したURLから以下のことをやっていきます。
- URLを加工して、ダウンロード用のURLにする
- 関数化し、見やすく
- 同じファイルがダウンロードされないように記録して、同じファイルをダウンロードしようとすると除外する。
これらを行っていきます。
コード解説
# 時間を計るライブラリをインポート
import time
#from Components import SettingDriver as Driver , get_url ,bbs_data as data
import time
from selenium.webdriver.common.by import By
#from selenium.webdriver.common.by import By
import re
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ChromeのWebDriverライブラリをインポート
from selenium.webdriver.chrome import service as fs
import os ,json
def geturl(value):
count=len(value["driver"].find_elements(By.XPATH,"//*[@class='docs-homescreen-list-item docs-homescreen-item-shared']"))
if value["howmanyfile"] is None : value["howmanyfile"] = count
urlitem =getURLItem(value)
return urlitem
def getURLItem(geturlItemvalue):
driver = geturlItemvalue["driver"]
num = 0
hover = []
urlitem = []
for i in range(geturlItemvalue["howmanyfile"]):
#以下のclassの値が違うかもしれないので、「存在しない」エラーが出た場合サイトを確認してみてください。
hover=driver.find_elements(By.XPATH,"//*[@class='docs-homescreen-list-item docs-homescreen-item-shared']")
time.sleep(1)#ロードができていない場合、取得できない場合があるので、間隔をあけている
print(len(hover))#ここでhoverの数が0の場合は読み込めていないとき。対策は、time.sleepを長くするか、hoverが0以外の時にのみ処理を実行するか。
hover[num].click()
title =driver.title
url = driver.current_url
print(title)
print(num,":", url)
urlitem.append({"url":url,"title":title})
driver.back()
time.sleep(2)#同様に間隔を空けている(hoverが0の時は再度処理をやり直すのを組み込んでも良い)
num = num + 1
return urlitem
#ChromeDriverのパスを指定
CHROMEDRIVER = "chromedriver.exe"
def SetDriver(value):
# ドライバー指定でChromeブラウザを開く
chrome_service = fs.Service(executable_path=CHROMEDRIVER)
options = Options()
#以下を加えないとエラーが出る。
#options.add_argument('--headless')
options.add_experimental_option('detach', True)
# プロファイルの保存先を指定
options.add_argument("--user-data-dir={}".format(value["user"]))
# 使用するプロファイルを指定
options.add_argument("--profile-directory={}".format(value["profile"]))
driver = webdriver.Chrome(service=chrome_service, options=options)
return driver
#保存先ファイルを指定
BASE_DIR = os.path.dirname(__file__)
SAVE_FILE = BASE_DIR + 'log.json'
#ログファイル(JSON形式)を読みだす
def load_data():
if not os.path.exists(SAVE_FILE):
return []
with open(SAVE_FILE, 'rt', encoding='utf-8') as f:
return json.load(f)
#ログファイルへ書き出す
def save_data(data_list):
with open(SAVE_FILE, 'wt', encoding='utf-8') as f:
json.dump(data_list, f)
#ログを追記保存
def save_data_append(value):
data_list = load_data()
data_list.append(value)
save_data(data_list)
#※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
#※※※※※※※※※※※※※※※※※※ここからユーザー記入欄※※※※※※※※※※※※※※※※※※※※※※※※※※※
#※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
#chrome://version/ を検索。プロフィールパスを転記。
driver = SetDriver({
"user":"C:/Users/<ユーザー名>/AppData/Local/Google/Chrome/User Data/",
"profile":"Default"
})
#ファイルをダウンロードする数を指定。(最大45)
filenum = 1
#※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
#※※※※※※※※※※※※※※※※※※ここまでユーザー記入欄※※※※※※※※※※※※※※※※※※※※※※※※※※※
#※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
time.sleep(1)
# Chromeを開いてGoogleにアクセスする
driver.get('https://docs.google.com/spreadsheets/u/0/')
#時間を時間を置く。
time.sleep(1)
print("~~~~~~~~~~URL取得を開始します。~~~~~~~~~~~~~~~~")
urlitem = geturl({
"driver":driver,
"howmanyfile":filenum
})
print("~~~~~~~~~~URLを{}個取得し終わりました。~~~~~~~~~~~~".format(filenum))
print("~~~~~~~~~~ダウンロード開始します。~~~~~~~~~~~~~~~~~")
#スクリーンショットを撮影したい場合
#driver.save_screenshot('selenium_schreenshot_test2.png')
#URLの加工処理&ダウンロード
for item in urlitem:
delete_url = re.sub(r'[^/]*$', '', item["url"]) + "export?format=xlsx"
if delete_url in load_data():
print("「{}」はダウンロード済みです。".format(item["title"]))
else:
save_data_append(delete_url)
print(delete_url)
driver.get(delete_url)
time.sleep(2.5)
# 画面を閉じる
driver.quit()
print("~~~~~~~~~~~ダウンロード完了しました。~~~~~~~~~~~~~~~~")
URLの加工処理では、取得したURLをurlitemに保存しているわけですが、そのURLの末尾を変えることでダウンロードができるURLにすることができます。
具体的には、
https://docs.google.com/spreadsheets/d/hogehogehoge/edit#gid=0
この「~~~/edit#git=0」 の部分を「export?format=xlsx」に変えることです。
今回はreメソッドで簡単に書き換えができたのでそちらを使っています。
↓実際に実行してみた結果(driverが起動してからの撮影)
実際に使ってみる手順
- インストールすべきものを準備
- まずは、以下のものをインストールしているか確認しましょう。していなければインストールします。
・Python
・selenium
・Chrome
・ChromeDriver(Chromeと同じバージョンのものを使うこと)
※それぞれのインストール方法は別途検索してください。
- Chromeのバックグラウンドインスタンスの停止
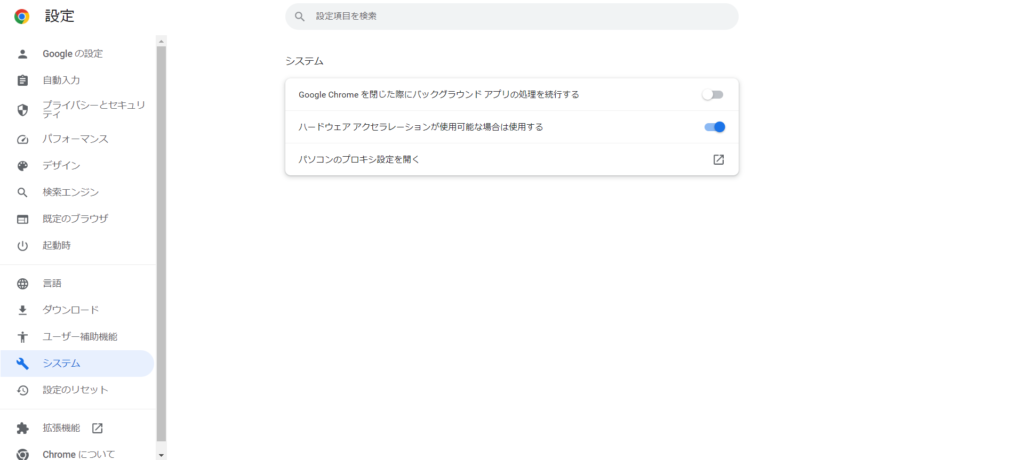
- Chormeの右上の「3ポチ」(三つの点があるやつ)をクリックして、その中の「設定」を選びます。
すると、以下のように設定画面がでるので、左のメニューバーから「システム」を選びます。
「GoogleChromeを閉じた際にバックグランドアプリの処理を続行する」をオフにします。
- SpreedSheetを閲覧できるアカウントのプロフィールパスを取得
- SpreedSheetにログインできるアカウントでChromeにログインしましょう。
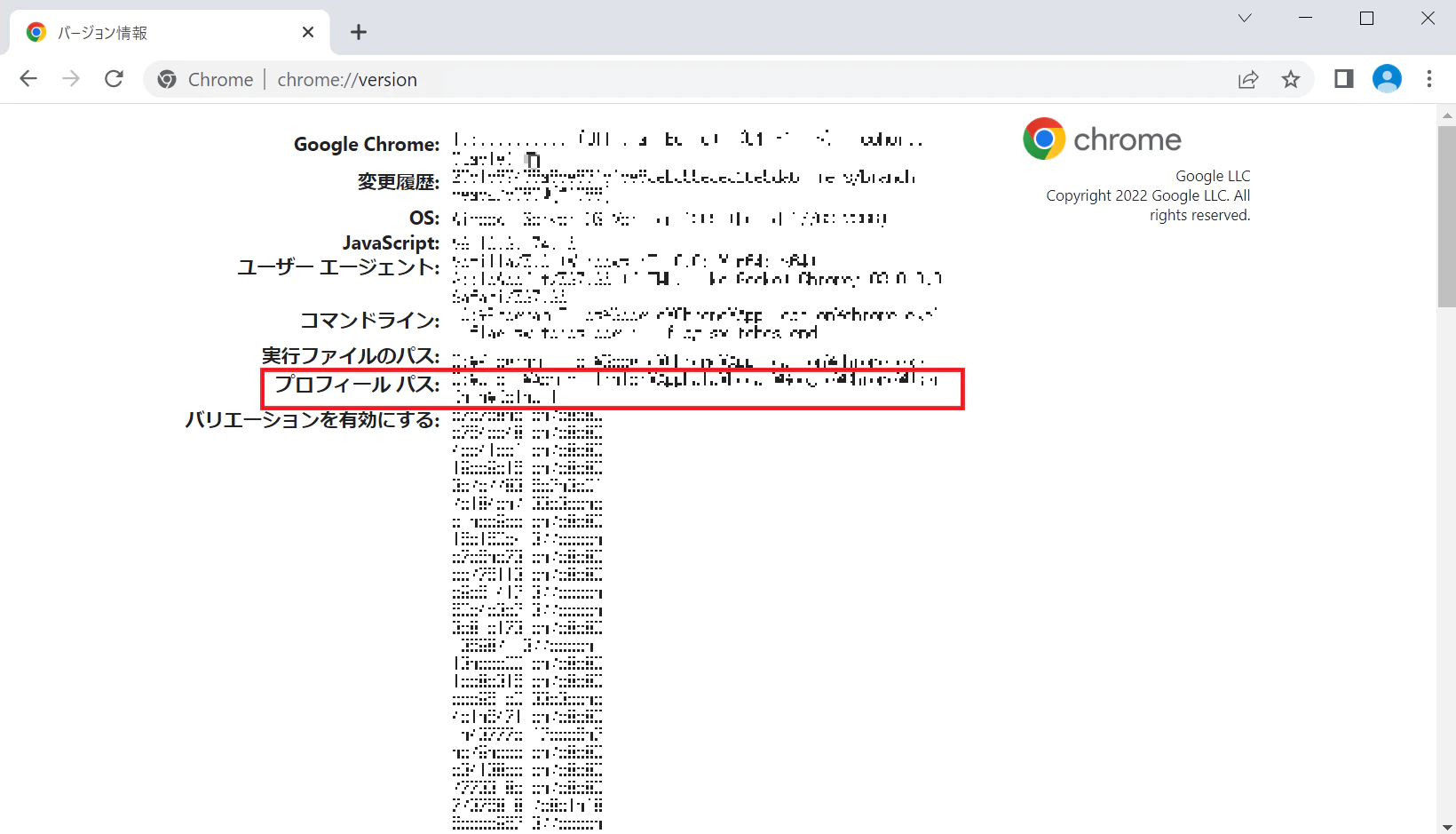
ログイン後、URLで以下を検索します。
chrome://version
こちらのプロフィールパスの部分を後で使うので、このページを参照できるようにしておいてください
- 適当なディレクトリを準備
- これから、開発を行っていくためのディレクトリを準備してください。
この中にファイルをコピーしていきます。
- ファイルを準備
- ①chrome.pyファイルを準備
上で紹介したコードをそのままコピーしてファイルに保存してください。(以降では、chrome.pyとしていますが、変更しても問題ありません)
②ChromeDriver.exeを準備
先ほど、ダウンロードしたChromeDriverのzipファイルに入っている「chromedriver.exe」を同じディレクトリに配置してください。
③log.jsonファイルの作成
新たにファイルを作成してください。名前を「log.json」ファイルにします。
そして、中に [] を入れるようにしてください。
最初に[]を入れておかないと、エラーになります。
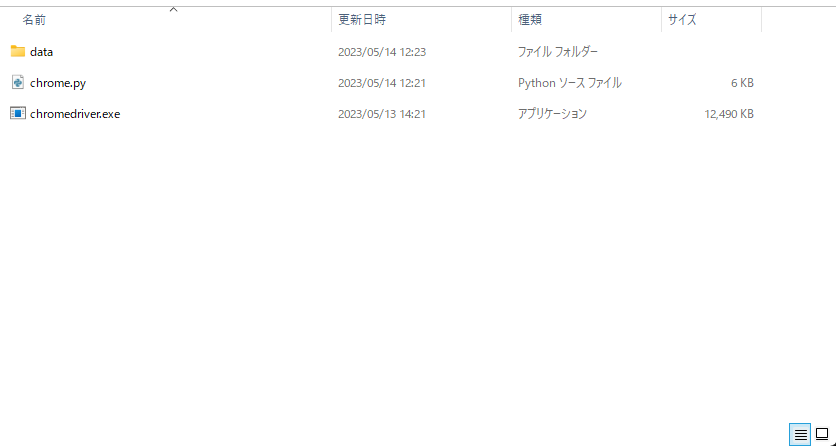
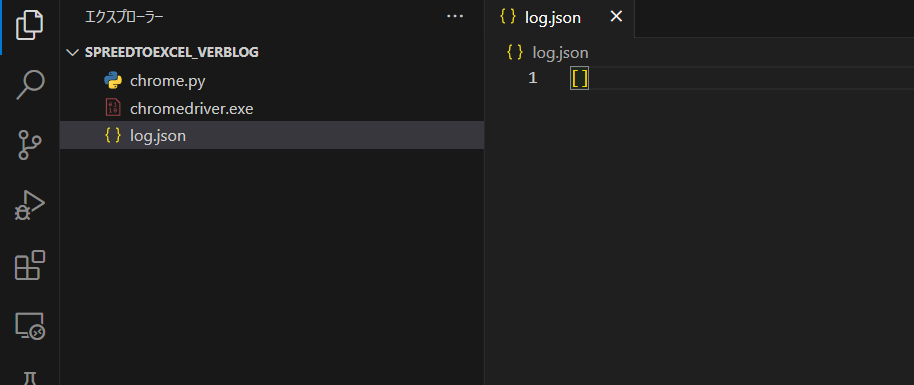
ディレクトリの構造とlog.jsonの中身。
- chrome.pyの中身を書き換える。
- 先ほど調べた「プロフィールパス」をここに書き加えます。
<例>
Driver = SetDriver({
"user" : "C:/Users/<ユーザー名>/AppData/Local/Google/Chrome/User Data/"
"profile" : "Profile 1"
})
Driver = SetDriver({
"user" : "<<この中を書き換える>>"
"profile" : "<<この中を書き換える>>"
})
filenum = <<ダウンロードする数>>
※ダウンロードする数は1でやってみて、成功してから変更してみてください。
- コマンドプロンプトで実行
- コマンドプロンプトを立ち上げます。
「cd」で該当のディレクトリに移動します。
「 python chrome.py」を入力し、エンター。
- 処理が始まり、ダウンロードが成功したらOK
- エラーが出た場合は、以下を見てみてください。
①Chromeが起動していないか。バックグランドでも起動していないか。
②プロフィールパスが間違っていないか。
→UserDataとなっていないか。空白を入れるのを忘れずに。
→「\」となっていないか。「/」にする。
- 一度ダウンロードに成功したファイルをもう一度ダウンロードしたい場合。
- log.jsonの[]の中身を削除してください。
[] は残すように。
削除してから再度実行してください。
まとめ
今回は、PythonのSeleniumを使ってGoogleSpreedSheetを一括でダウンロードする方法について解説していきました。
その1の方で前準備について詳しく解説しているのでまだ読んでいない方は読んでみてください。
-150x150.jpg)
-300x169.jpg)
